
Я умею объяснять сложное без магии и хайпа, а потом превращать это в аккуратные автоматизации. Сегодня про то, как малому бизнесу приручить ИТ-риски и не утонуть ни в бумагах, ни в штрафах. Будет по делу: как понять, что именно угрожает вашим системам, как выстроить простую систему управления рисками, какие методы и меры реально работают, где подключить n8n и Make.com, как вплести ИИ-агентов и не нарушить 152-ФЗ. Поговорим о том, какие вопросы задавать себе и подрядчикам, какие метрики держать на виду и как выстроить процесс не на один раз, а навсегда. Если коротко, цель простая - чтобы контент делался сам, инциденты тушились быстро, а люди возвращали себе время.
Время чтения: ~15 минут
Одна из моих первых задач во внутреннем аудите ИТ выглядела почти невинно: проверь, почему резервные копии есть, а восстановление не получается. Я пришла, спросила пару вопросов, посмотрела логи, и поняла, что бэкапы есть, но на один и тот же диск, да еще и с правами администратора у всех подряд. Ничего экстра, просто чья-то спешка и недосмотр. В итоге время восстановления было не дни, а никогда, а бизнесу казалось, что все под контролем. Тот случай научил меня одному простому правилу: ИТ-риски редко кричат, чаще шепчут, а значит их управление должно быть системным, понятным и очень конкретным. Не про «повысьте осведомленность», а про «вот шаги, вот метрики, вот проверка».
Сегодня владельцам и руководителям малых компаний досталось сразу с двух концов. С одной стороны, атаки стали дешевыми и автоматизированными, ботам не важно, у вас 20 сотрудников или 2000. С другой стороны, ресурсов на полноценные SOC, SIEM и армии безопасников обычно нет, зато есть подрядчики, облака, Телеграм-боты и куча легаси. Поэтому управление рисками в ИТ я всегда строю в формате минимально достаточной системы: никаких толстых регламентов, только живые документы, автоматические оповещения и регулярные короткие циклы контроля. В этой статье соберу мой рабочий подход - от карты активов и риск-реестра до интеграций в n8n и Make.com, ИИ-агентов для первичной triage и простых, но честных метрик.
Почему малый бизнес уязвим и что считать риском
Начнем с терминов, но человеческим языком. Риск - это влияние неопределенности на ваши цели, а цель в малом бизнесе обычно проста: продавать, оказывать услуги, не попасть на штрафы и не терять клиентов. Угроза - источник неприятности, которая может ударить по вашим системам, данным или репутации. Уязвимость - дырка в заборе, куда удобно пролезть. Сценарий риска - связка из угрозы, уязвимости и актива, например: «фишинг-ссылка + сотрудник без тренинга + доступ к CRM». Важно договориться о границах: сюда же относятся операционные ИТ-риски, риски ИТ-инфраструктуры, риски ИТ-технологий и риски ИТ-проекта, если вы параллельно внедряете новый сайт или ERP. Если это влияет на достижение ваших целей - это наш кандидат в реестр, остальное уходит в общий бэклог улучшений.
Почему уязвимость выше именно у малого бизнеса. Во-первых, процессы часто держатся на нескольких людях, и если один админ заболел, доступы зависли вместе с задачами. Во-вторых, подрядчики и облачные сервисы меняются, а контроль за ними фиксируется в мессенджере, а не в договоре и не в чек-листе. В-третьих, привычка «потом настроим» в ИТ приводит к накоплению технического долга, который в какой-то момент становится громким. Наконец, базовые меры безопасности вроде обновлений, MFA и ограничений по доступу кажутся «потом сделаем», хотя это и есть самые дешевые методы управления рисками. Я видела разные варианты и почти всегда начинала не с покупки чего-то, а с расстановки приоритетов и коротких регламентов, которые понятны команде.
Какие угрозы типичны. Фишинг и компрометация почты, кража сессий в браузере, вымогатели с шифрованием, утечки из мессенджеров, неаккуратная публикация конфигов в публичные репозитории, инциденты у подрядчиков, простые DDoS на сайт, банальные ошибки конфигураций в облаке. Из юридических - обработка персональных данных без достаточных мер защиты и документальной опоры под 152-ФЗ, что чревато штрафами и предписаниями. Из операционных - простой из-за падения сервера, сбой интеграций с платежами, сломанный бэкап, чей-то случайный доступ к общему диску. Все это складывается в понятное поле, где оценка и управление рисками становится не страшным словом, а рутиной, как мыть посуду: лучше каждый день по чуть-чуть, чем раз в месяц, но до ночи.
Сколько это стоит в реальности. Простой интернет-магазина на сутки - это недополученная выручка, скидки недовольным, перегруз поддержки, плюс ретурны из-за нарушенных сроков. Утечка базы клиентов - репутационные потери, письма с извинениями, следом запросы от регуляторов, а дальше аудит и предписание. Даже один взлом почты директора с последующей перепиской об оплатах часто обходится дороже, чем годовая подписка на нормальные средства защиты и пара выходных на настроку. Это не страшилка, просто арифметика, которую стоит один раз посчитать у себя и использовать как аргумент, когда вас просят «потом».
Риск - это всегда про выбор, но хороший выбор появляется только там, где есть прозрачность: список активов, владельцы, вероятности, влияние и простые правила реакции.
Здесь важно принять, что идеальной защиты нет, есть разумные меры управления рисками и последовательный контроль. Вас спасут не сертификаты, а привычка смотреть на карту активов и спрашивать себя пару раз в месяц: что у нас появилось нового, что изменилось, где у нас сейчас «слабое звено». А дальше подключаем методы управления рисками и двигаемся к системе, которая живет вместе с бизнесом, а не мешает ему. Этот мостик ведет к следующей теме - как построить систему без бюрократии.
Простая система без бюрократии
Я начинаю с минимально достаточной системы управления рисками без толстых регламентов. Первое - карта активов: список того, без чего вы не можете работать. Это не философия, а таблица с 4 колонками: название актива, владелец, где лежит, как даются доступы. Второе - роль владельца актива: один человек отвечает за соответствие, доступы, изменения и метрики. Третье - риск-реестр: одна таблица, где риск описан в формате сценария, есть вероятность, влияние, контроль и статус. Четвертое - короткий цикл обновления: раз в 2 недели быстрый пересмотр ключевых рисков и контрольных мероприятий. Пятое - уведомления: любые критические изменения в активах или инциденты - сразу в канал, а не в «потом». Система получается легкой, но живой.
Зрелость можно измерить в четырех шагах. Нулевой уровень - хаос, никто не знает, у кого какие доступы, инциденты разбираются постфактум. Первый - инвентаризация активов и назначение владельцев. Второй - риск-реестр и базовые политики: пароли, MFA, обновления, бэкапы, доступы. Третий - автоматизация оповещений и контрольных процедур, появление метрик и KRI. Четвертый - интеграция с процессами компании, когда риск обсуждается не только в ИТ, но и на уровне продукта и продаж. Хорошая новость в том, что переход с нулевого до второго уровня занимает недели, а не годы, если есть дисциплина.
Для визуализации я люблю броско-простые схемы. Например, через UML-нотацию можно нарисовать два-три диаграммы: акторы и их доступы, основные потоки данных между системами и границы доверия. Ничего художественного, просто наглядно. Особенно, когда у вас подрядчики и небольшой зоопарк сервисов. И еще один штрих - матрица риска с 3 уровнями вероятности и 3 уровнями влияния, никаких 5х5 и дробей, чтобы команда не спорила о десятых долях. Сдвигаем фокус туда, где «высокое-высокое», и начинаем с ножниц, а не с кисточки.
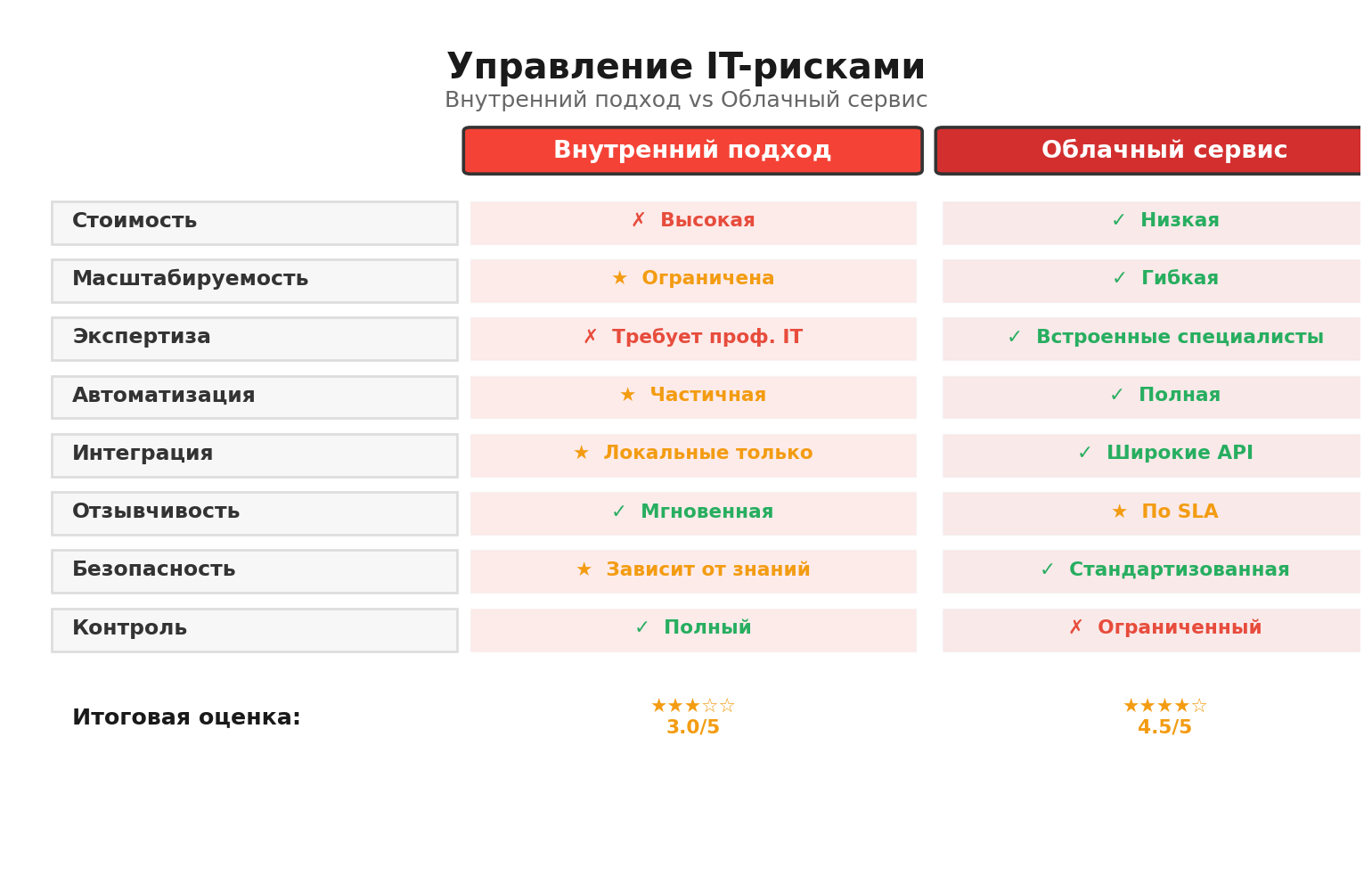
Где здесь место автоматизации. У меня в привычках - строить небольшой слой на n8n или Make.com: выгрузка активов из облаков и SaaS, сверка с реестром, уведомления, контроль MFA и статуса обновлений, сбор инцидентов в единый бортовой журнал. Никакой магии, просто оркестрация. Если нужен умный разбор оповещений - подключаем ИИ-агента для triage: он помечает ложные срабатывания, классифицирует по типу и советует первые действия. Я обычно добавляю два триггера: «новый актив без владельца» и «высокая уязвимость без патча 7 дней» - и на этом этапе дисциплина заметно вырастает.
Финальный штрих - договориться о языке. Используем одинаковые определения, фиксируем формулы вероятности и влияния, описываем методы управления рисками: избегание, снижение, перенос, принятие. Еще одно правило - меряем не чувства, а показатели: наличие MFA, доля обновленных узлов, время восстановления, время реакции на инцидент. Согласовав базу, мы получаем систему, которая не зависает на согласованиях, а двигается в сторону конкретных действий. Дальше - к инструментам, которые помогут держать все это на плаву.
Инструменты: от автоматизации до резервных копий
Инструменты зависят от масштаба и бюджета, но есть базовая тройка, которую я почти всегда ставлю первой. Первое - контроль идентификаций и доступов: единая точка входа, пароли в менеджере, MFA везде, где можно, роль-права по минимуму. Второе - управление обновлениями: централизованная установка патчей, мониторинг критических уязвимостей, запрет устаревших протоколов, проверка конфигураций в облаках. Третье - резервное копирование и регулярные тесты восстановления по сценарию «горячо и быстро», чтобы не изучать документацию в момент аварии. Это и есть меры управления рисками, которые дают 70% эффекта за 30% усилий.
Теперь про автоматизацию. В n8n и Make.com я собираю сборку из датчиков и действий: вебхуки от систем мониторинга, логи из серверов и облаков, события из систем контроля версий и мессенджеров. Простые правила: если появилась новая учетная запись - проверь владельца и группу, если обнаружена критическая уязвимость - открой задачу, поставь метку «высокий», отправь уведомление ИТ и владельцу актива. Когда нужна первая помощь, ИИ-агент анализирует контекст и предлагает шаги: изолировать узел, отключить подозрительный доступ, проверить токены. И да, это все можно сделать аккуратно в white-data-зоне, с логированием и без лишних персональных данных.
Антивирусы и EDR остаются обязательными, пусть и банально. Плюс фильтрация почты, ограничение вложений, sandbox для ссылок, блокировка макросов. Для облаков - политики по умолчанию с минимальными правами, шифрование на дисках и в передаче, ревизия публичных бакетов. Для мессенджеров - правила по сохранению истории, запрет передачи файлов с чувствительными данными, а лучше - вынос таких вещей в защищенные каналы. Для доступа извне - VPN, ограничение по IP, а для администрирования - раздельные учетные записи и аудит действий. Монотонно, да, зато эффективно.
Лучший инструмент - тот, который команда реально использует. То, что невидимо, забывается, а то, что мешает, отключают.
Про резервные копии отдельно. Я прошу настроить правило 3-2-1: 3 копии, 2 носителя, 1 копия вне площадки. Для операционной реальности малого бизнеса чаще срабатывает 3-1-1, если архитектура проста, но критична скорость восстановления. Важно не только делать бэкап, но и регулярно проходить процедуру восстановления, не на словах, а руками. По регламенту - раз в месяц, по критичным системам - каждую неделю быстрый тест на отдельном стенде. Если восстанавливать скучно и долго - автоматизируйте скриптом и уведомлением, пусть n8n кинет отчет утром в понедельник, когда кофе еще не остыл.
Чем дополнить. Журналы аудита в централизованное хранилище, базовый SIEM-слой или его легкая альтернатива, ревизия инфраструктуры сканером уязвимостей, проверка SaaS-настроек, политика по персональным данным под 152-ФЗ с понятными уровнями доступа и сроками хранения. Если хотите оживить картину - добавьте дешевые сенсоры: honeypot на отдельном хосте для сигналов об активных сканах или поддельные учетные записи для ловли грубых атак. Этого достаточно, чтобы перейти к процессу, где оценки и решения принимаются быстро и не на эмоциях.
Пошаговый процесс оценки и управления
Дам простой маршрут на 10 рабочих дней, который у меня прижился в командах разного размера. День 1-2: инвентаризация активов и назначение владельцев. День 3: фиксация текущих правил доступа, MFA, обновлений и бэкапов. День 4: первичная идентификация рисков по шаблону угроз и уязвимостей. День 5: быстрая оценка вероятности и влияния по шкале 1-3 и формирование матрицы. День 6: определение методов управления рисками для верхних 5 сценариев - избегать, снижать, переносить или принимать. День 7-8: настройка автоматических оповещений и контрольных процедур. День 9: запуск метрик и KRI, договоренность о периодичности обзора. День 10: короткая презентация владельцам бизнес-процессов, чтобы язык и ожидания совпали. Это не марафон, это спринт, который дает основу.
Как считать риск без калькулятора на 20 колонок. Я использую качественную оценку с числовыми уровнями: вероятность от 1 до 3 и влияние от 1 до 3, произведение дает приоритет. Для влияния беру три среза: финансовое, юридическое, репутационное. Согласуем пороги на стене или в wiki, чтобы не спорить по каждому пункту. Важно: раз в месяц пересматриваем факторы, потому что мир меняется быстро. Для рисков ИТ-проекта применяю тот же подход, только добавляю время и зависимость от подрядчиков, чтобы не терять «критические пути» в проектном плане.
Контроль - не бумага, а действие. Для каждого верхнего риска фиксируем конкретные меры управления рисками: что делаем, кто отвечает, какую метрику смотрим. Если переносим - значит есть договор страхования или штрафы в контракте с подрядчиком. Если принимаем - есть документированное решение владельца, понимание последствий и план B. Если снижаем - то это не «повысьте осведомленность», а «включаем MFA по всем учеткам до пятницы» и «внедряем ежедневные инкрементальные бэкапы с еженедельным полным». Так рождается процесс управления рисками, который выдерживает проверку вопросом «а что вы сделали за неделю».
Методики важны, но побеждает цикл: определить - измерить - сделать - проверить - повторить.
Метрики и KRI. Несколько показателей дают ясность: доля активов с владельцем, доля учетных записей с MFA, доля узлов на актуальных обновлениях, среднее время обнаружения и реакции, успешность тестового восстановления, количество инцидентов на 100 сотрудников, закрытие задач по уязвимостям в срок. Для 152-ФЗ добавляю долю сотрудников, прошедших обучение по персональным данным и процент систем с ограничением доступа по ролям. На панели вижу зеленое, желтое, красное и, если честно, тут и начинается реальная работа - мы не спорим, а корректируем.
ИИ-агенты вплетаются аккуратно. Их зона - triage оповещений, генерация черновиков отчета об инциденте, напоминания владельцам, первичная классификация журналов. Я не отдаю им решение, только рутину. Если делаете агента для обработки писем сервис-деска - обучите на ваших историях и не храните персональные данные лишний раз. А для дополнительной визуализации составьте парочку UML-диаграмм потоков данных, чтобы видеть, где точка входа угроз и какие границы доверия у вас реально есть, а не на словах. Процесс выстроен - можно говорить о результатах.
Что меняется после внедрения
Первое, что замечают команды - снижается хаос. Появляется карта активов, и вопросы «у кого доступ и где хранится» занимают минуты, а не день. Риск-реестр превращается в календарь действий, а не в парковку тревожных мыслей, и управлению ИТ-рисками наконец-то есть где жить. Инциденты перестают быть «сюрпризом», потому что оповещения приходят тем, кто может действовать, а не всем подряд. Время восстановления падает, потому что сценарий отработан, а бэкап проверен на практике. Ставим галочки не ради галочек, а потому что бизнес верит в эффект и его видит.
Второе - прозрачность для руководства. Когда на одном экране видны метрики, вопросы снимаются быстрее. Система управления рисками перестает быть черным ящиком, появляется общая картина и язык. Для 152-ФЗ мы можем показать, какие меры есть в конкретных системах, кто отвечает и как часто проверяем, и это серьезно экономит время при общении с проверяющими. Опять же, никакой магии, просто дисциплина. Приятный побочный эффект - растет культура документации, а это сильно помогает при масштабировании команды.
Третье - деньги. Снижение простоев и инцидентов ощутимо, когда у вас интернет-магазин или сервис с многотысячной аудиторией. Плюс экономим на тушении пожаров и срочных закупках «прямо сейчас», потому что план есть заранее. Автоматизация на n8n и Make.com снимает рутину, которую обычно выполняли руками, и возвращает команде часы. Иногда эффект приходит уже от двух триггеров: «новая учетная запись без MFA» и «критическая уязвимость без патча больше 7 дней», потому что именно там и прячутся тяжелые инциденты.
Мини-история. Небольшое агентство, 40 человек, куча SaaS и несколько серверов у провайдера. За 3 недели мы собрали реестр активов, включили MFA, почистили группы, завели автоматические проверки, настроили ежедневные инкрементальные бэкапы, а раз в пятницу - тест восстановления сайта на отдельном хосте. В первый месяц поймали две странности: лишний доступ бывшего подрядчика и открытый бакет с логами, который раньше никто не замечал. Никаких чудес, просто база. Через полгода ребята уже сами добавляли новые интеграции и метрики, а у меня остался один ритуал - ежемесячный обзор ключевых рисков и их статуса. Это и есть устойчивость.
Подводные камни и как их обходить
Главный враг - бумажная безопасность. Документы есть, а жизнь идет отдельно. Лечится связкой: живые чек-листы, регулярные короткие ревью, напоминания и автоматические задачи. Второй враг - надежда на один инструмент. SIEM не заменит дисциплину, ИИ-агент не возьмет на себя ответственность, а антивирус не поставит патч. Третий - культура «все через админа». Система ломается, если каждый вопрос упирается в одного человека, поэтому назначаем владельцев активов и распределяем ответственность.
Человеческий фактор. Сотрудники устают от новых правил, особенно если они мешают. Поэтому каждое правило должно быть объяснимо и экономить время, а не красть его. MFA - удобно с биометрией и менеджером паролей, бэкап - не больно, если автоматизирован, обновления - безопасно, если есть окно и тестовый контур. Обучение делаем коротким и регулярным, с примерами из жизни компании, а не с абстрактными слайдами. И еще одно - не стыдиться признавать ошибки, это экономит деньги. Я иногда пишу себе заметки в скобках, чтобы не забыть мелочи и потом поправить курс.
Технический долг и интеграции. В n8n и Make.com все кажется простым, пока не надо поддерживать. Сразу фиксируем версии, используем репозитории для сценариев, пишем пару тестов на критичные ветки и делаем бекап конфигураций. По интеграциям - не тянем данные лишний раз, особенно персональные, и помним про шифрование в пути и на хранении. Иногда лучше прокинуть сигнал, а не весь массив событий. Да, это меньше данных для ИИ, зато безопаснее и понятнее.
Еще одна мелочь - переоценка сложных матриц и недооценка простых проверок. Я видела риск-модели на десятки параметров, которые никто не трогал годами, и видела таблицу на одну страницу, которая реально работала. Для малого бизнеса выигрывает простота. И, наконец, коммуникации: если бизнес не понимает, что вы делаете, он не будет поддерживать систему, а значит она потихоньку рассыплется. Раз в месяц 30 минут разговора решают удивительно много вопросов. Дальше - практический чек-лист, который можно взять и пройти.
Практические шаги на месяц
Ниже короткая программа, которая помогает запустить процесс без лишней суеты. Сформулирована в формате «минимум движений - максимум пользы», с опорой на методы управления рисками, которые реально встанут в расписание. Если чувствуете, что перегружаю деталями, отложите один пункт на следующую неделю, но не бросайте цикл - только так система станет привычкой, а не проектом раз в год.
- Неделя 1: составьте карту активов с владельцами и отметьте критичные системы. Проверьте, где лежат персональные данные и какой уровень защиты требуется по 152-ФЗ. Заведите общий документ в wiki и договоритесь о формате обновления. Это база для любой системы управления рисками.
- Неделя 2: включите MFA и настройте менеджер паролей. Почистите группы доступа, отключите неиспользуемые учетные записи, для администрирования заведите отдельные аккаунты. Зафиксируйте правило минимально достаточных прав и заведите регулярную проверку раз в 2 недели.
- Неделя 3: сделайте резервные копии по правилу 3-2-1 и проведите тест восстановления. Документируйте сценарий восстановления в коротком чек-листе, добавьте напоминание в календарь. Пусть n8n отправляет отчет по результатам теста по понедельникам.
- Неделя 4: настройте автоматические оповещения и базовую панель метрик. Включите проверки критических уязвимостей и статуса обновлений, заведите задачи по устранению с дедлайнами. Подключите ИИ-агента для triage оповещений, чтобы снизить шум и ускорить реакцию.
- Постоянно: раз в месяц пересматривайте риск-реестр, удаляйте устаревшее и добавляйте новое. Раз в квартал сравнивайте фактические метрики с целевыми. Держите короткую встречу с владельцами активов и руководителями процессов. Поддерживайте реестр и схемы в актуальном состоянии.
Короткое послевкусие вместо громких выводов
Если убрать громкие слова, управление рисками - это привычка видеть картину целиком и не откладывать мелкие правки. Карта активов, владельцы, риск-реестр на одну страницу, пара автоматических триггеров, регулярные тесты восстановления и честные метрики - этого достаточно, чтобы малый бизнес перестал быть легкой добычей и спокойно рос. Мне нравится, когда процесс живет внутри команды: не как разовая кампания, а как часть ритма, где раз в неделю 30 минут уходит на контроль и улучшение. Это не про страх, а про уважение к своему времени и данным клиентов.
Технически сложные вещи можно объяснить просто, а потом автоматизировать так, чтобы не зависеть от настроения и памяти. Тут помогают n8n и Make.com, легкие ИИ-агенты для triage и добротная операционная дисциплина. Несколько правил - минимум прав, MFA везде, обновления вовремя, бэкап с восстановлением, контроль подрядчиков и SaaS - закрывают большую часть сценариев. Остальное - настройка под ваш контекст и здоровая внимательность к деталям. Если в какой-то момент поймаете себя на мысли «кажется, мы все делаем правильно», значит система работает. Если нет - не страшно, это поправимо, я тоже иногда слегка спотыкаюсь и возвращаюсь к списку.
Небольшое приглашение к практике
Если хочешь структурировать эти знания и собрать свой рабочий контур без избыточной теории, у меня есть спокойные текстовые разборы и примеры автоматизаций с n8n и Make.com. Я периодически делюсь наблюдениями и рабочими шаблонами на сайте MAREN, а еще веду камерный канал в Telegram, где разбираю нюансы и отвечаю на конкретные вопросы по процессу. Для тех, кто готов перейти от теории к практике, это удобная среда, чтобы спокойно собрать систему под себя и вернуть себе время.
Частые вопросы по этой теме
С чего начать, если ничего не настроено
Сделайте карту активов и назначьте владельцев, а затем включите MFA и настройте бэкапы с тестовым восстановлением. Параллельно заведите риск-реестр на одну страницу и выберите 3-5 ключевых метрик. Это даст быстрый эффект и основу для развития.
Как часто пересматривать риски и метрики
Минимум раз в месяц пересматривайте верхние риски и проверяйте метрики, а при заметных изменениях в архитектуре - внепланово. Для критичных систем держите еженедельный короткий цикл проверок. Регулярность важнее глубины одноразового анализа.
Какие инструменты обязательны в малом бизнесе
MFA, менеджер паролей, централизованные обновления, антивирус или EDR, резервное копирование с регулярным тестом восстановления. Плюс автоматические оповещения и база метрик. Остальное добавляйте по необходимости.
Нужны ли сложные матрицы и оценки вероятности
Нет, достаточно простых шкал 1-3 по вероятности и влиянию. Сложность не добавляет точности, если команда не успевает ей пользоваться. Главное - договориться о порогах и регулярно пересматривать их.
Как использовать ИИ-агентов безопасно
Отдавайте им рутину: классификацию событий, черновики отчетов, подсказки по первым шагам. Не передавайте избыточные персональные данные, логируйте решения и оставляйте финальное слово за человеком. Это снижает шум и ускоряет реакцию.
Как управлять рисками проекта при внедрении новой системы
Добавьте в реестр рисков проектные сценарии: задержка поставок, недостаточная интеграция, уход ключевого подрядчика. Для каждого сценария пропишите меры и дедлайны, закрепите владельца и метрику. Синхронизируйте контроль с планом проекта.
Как убедить руководство выделить время на процесс
Покажите простую математику простоя и стоимости одного инцидента в сравнении с временем на базовые меры. Приложите список быстрых действий на 2-3 недели и согласуйте метрики. Когда виден эффект, сопротивление падает.


