
Автоматизация n8n для транскрибации аудио через Whisper API в России - это не только про экономию времени на расшифровке, но и про аккуратный танец вокруг 152-ФЗ и white-data. Я часто вижу, как российские специалисты берут модный туториал, прикручивают зарубежный API и искренне удивляются, когда коллеги по безопасности начинают нервно подёргивать глазом. В этой статье я разложу по шагам, как собрать рабочий конвейер транскрибации аудио в текст на базе системы автоматизации n8n так, чтобы он не противоречил требованиям по персональным данным и реально снимал рутину. Мы поговорим о том, как устроен жизненный цикл записи - от момента, когда клиент сказал «алло», до точки, где у вас в CRM лежит обезличенный текст. Разберем архитектуру, типовые ошибки, интеграцию с Whisper и что учитывать российскому бизнесу уже сейчас, пока регулятор только разогревается.
Зачем вообще трогать транскрибацию и где здесь n8n
Я помню первый «ручной» день, когда мне пришлось расшифровать около двух часов созвонов по проекту: к концу второй записи кофе остыл, а вера в человечество ушла куда-то вместе с пятой страницей заметок. Тогда я в очередной раз подумала, что транскрибация аудио в текст - идеальный кандидат на автоматизацию через n8n, и уж точно не то, чем должен заниматься человек с нормальным чувством самосохранения. В реальных российских компаниях эти часы копятся незаметно: колл-центр, консультации по записи, внутренние встречи, брифы с клиентами, голосовые из мессенджеров - а потом кто-то сидит ночью и добивает протоколы. Если это знакомо, значит, вы целевая аудитория этой статьи, особенно если слово «152-ФЗ» вызывает у вас лёгкое покалывание в затылке. Здесь хорошо работает связка ai агенты и автоматизация с n8n: один раз задумываем конвейер, дальше он крутится фоном, а вы занимаетесь тем, что действительно приносит ценность.
Чтобы было проще визуализировать, как вообще выглядит такой конвейер, я опираюсь на типовой workflow, который использую в своих проектах.
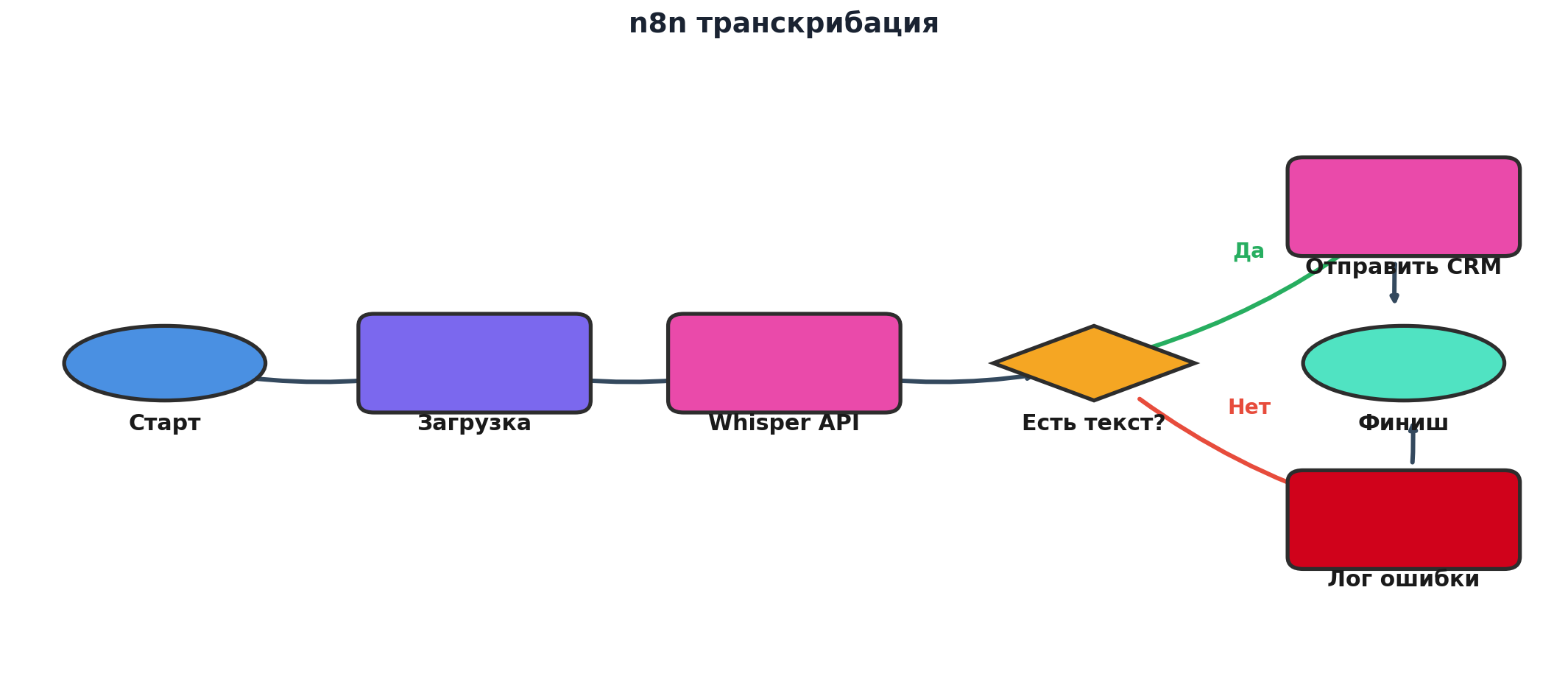
Я заметила, что самый частый вопрос не про то, «можно ли сделать транскрибацию аудио онлайн бесплатно», а про «как сделать так, чтобы нас за нее потом не наказали». Здесь Россия добавляет свои нюансы: регуляторные требования, локализация, white-data, отдельные согласия, биометрия голоса - и вот вы уже рисуете не только блок-схему n8n workflows автоматизации, но и карту обработки персональных данных. Автоматизация бизнеса n8n в этой зоне превращается из милой игрушки в серьёзный инструмент, который либо экономит сотни человеко-часов в год, либо добавляет вам головной боли на проверке Роскомнадзора. Дальше я покажу, как остаться в первой группе.
Что меняется в 2024–2025 и почему это касается даже маленьких команд
На практике всё осложняется тем, что автоматизация ии n8n не живет в вакууме: параллельно усиливаются требования к локализации баз данных, к формату согласий и к обезличиванию. Если вы в России собираете аудио с голосом граждан РФ и превращаете его в текст, вы почти наверняка попадаете под 152-ФЗ, а значит, вопрос «где лежит запись и кто ее обрабатывает» становится не просто техническим. Регулятор с 2025 года ожидает, что первичный цикл обработки проходит в РФ, а белые данные действительно белые, то есть обезличивание не фикция в стиле «переименовали Колю в Клиента 1». Это критично, потому что типичный конструктор автоматизации через n8n легко тянется к модным зарубежным API, а вот юристы потом тянутся к успокоительному. Если вы строите систему автоматизации n8n сейчас, есть смысл сразу смотреть на неё глазами DPO, а не только разработчика или продакта.
Чтобы не тонуть в абстракциях, я часто объясняю это через привычный образ колл-центра, где транскрибация аудио и видео нужна не ради красоты, а ради реального контроля качества и аналитики.
Представь себе стопку записей звонков, которые кто-то должен разобрать к утру. С автоматизацией n8n эта стопка превращается в очередь задач, которые крутятся по расписанию, а твоя задача - только заглянуть в дашборд, а не в текстовый ад из 200 страниц.
Получается, что сейчас самое время смотреть на транскрибацию аудио в текст онлайн не как на разовый эксперимент, а как на постоянный сервис внутри компании. И если уже на старте заложить архитектуру с учетом локализации, обезличивания и журналирования действий, вы сильно сэкономите себе нервы, когда придет первый запрос от службы безопасности или внутреннего аудита. Чуть дальше я разложу, какие именно точки этого конвейера критичны для комплаенса, а какие можно собирать по принципу «как удобнее команде».
Кому этот гайд реально пригодится в работе
Я писала этот текст в первую очередь для тех, кто уже трогал n8n руками или хотя бы видел Make.com, но при этом не хочет каждый раз спорить с безопасниками по поводу очередного webhook-а в Штаты. Это продакты и тимлиды, которые отвечают за автоматизацию процессов n8n в отделе продаж или клиентском сервисе, это внутренние аудиторы и риск-менеджеры, которым нужно объяснить ИТ-команде, где заканчивается творчество и начинаются регуляторные рамки. Ну и, конечно, все, кто делает свои проекты, записывает консультации, ведет курсы и устал вручную делать транскрибацию аудио онлайн бесплатно в очередном сервисе, а потом копировать текст по кусочкам. Я не буду продавать никакие «волшебные кнопки», мы пройдемся по архитектуре, белым зонам, типовым конфигурациям и покажем, как n8n workflows автоматизации помогают приручить ИИ-агентов так, чтобы они не тащили ваши данные за рубеж.
Иногда мне пишут в Telegram после статей: «Я думал, n8n - это про игрушечные интеграции, а ты его тянешь в серьёзную инфраструктуру». И да, я действительно отношусь к нему как к оркестратору, который может говорить и с транскрипционными моделями, и с системами комплаенса, и с SIEM. Если позволить себе мыслить не «как подцепить ещё один сервис», а «как построить устойчивый конвейер обработки данных», транскрибация через n8n перестает быть экспериментом и становится базовым сервисом, как почта или CRM. Дальше пойдём от рисков к решению: сначала разберёмся, где именно транскрибация превращается в профессиональный спорт по 152-ФЗ.
Как понять, что транскрибация аудио в России - это уже зона риска
Когда я первый раз пришла к юристам с идеей автоматизировать транскрибацию аудио через n8n и Whisper API, разговор начался с простого вопроса: «А ты уверена, что там нет персональных данных и биометрии?» На этом месте многие разработчики честно зависают, потому что в голове картинка: «ну это же просто голосовое сообщение из мессенджера». На практике почти каждое такое сообщение содержит имя, телефон, иногда адрес и массу косвенных идентификаторов, а сам голос легко тянет на биометрический признак. Это означает, что как только вы начали транскрибацию аудио в текст, вы создали новую форму персональных данных, подпадающих под 152-ФЗ. И уже неважно, воспринимаете вы это как «быструю расшифровку для себя» или как часть бизнес-процесса - регулятору интереснее факт, а не мотивация.
Чтобы зафиксировать эту мысль, я часто использую короткую формулу, которую полезно проговорить с командой до старта любого проекта на автоматизацию через n8n.
Любое аудио, где человек говорит о себе или других, по умолчанию рассматриваем как потенциальные персональные данные, пока не доказали обратное.В России к этому добавляется тренд на усиление требований: с 2025 года локализация баз влияет не только на «где лежит CRM», но и на то, где вы технически обрабатываете запись, прежде чем отдать её модели. Если автоматизация n8n отправляет звук в зарубежный Whisper API, а там сидит голос гражданина РФ, ваш «удобный конвейер» может зайти в прямой конфликт с идеей первичной обработки на территории РФ. Я заметила, что многие вспоминают об этом уже на этапе подписания акта по проекту, когда всё собрано и красиво работает, но менять инфраструктуру больнее, чем заложить правильный маршрут сразу. Здесь лучше сделать паузу на этапе архитектуры и проговорить, какие категории аудио вы будете крутить через ИИ агенты и автоматизация с n8n, а какие нет.
Чтобы не быть голословной, я часто показываю командам сравнительную картинку: слева - «как хочется», справа - «как придётся сделать, если учитывать реальность 152-ФЗ и Роскомнадзора».

На практике риск возрастает в нескольких типичных сценариях: колл-центр записывает все звонки для контроля качества, онлайн-школа держит библиотеку консультаций, юристы сохраняют звонки клиентов, а продуктовая команда переписывает созвоны с пользователями. Во всех этих случаях транскрибация аудио в текст онлайн бесплатно через зарубежный сервис без локализации выглядит привлекательно технически, но плохо стыкуется с идеей защищенного хранилища в РФ и понятного жизненного цикла данных. Если добавить сюда биометрический аспект голоса (а он почти всегда всплывает, когда кто-то вдруг решает использовать голос для аутентификации), получается довольно взрывоопасная смесь, в которой автоматизация процессов n8n должна не только соединять сервисы, но и разводить риски.
Как согласия и уведомления ломают красивую картинку
Я заметила, что многие смотрят на согласие как на скучную бумажку, которую «юристы что-то там добавят в политику». В стеке транскрибации это не работает: отдельное согласие на запись и транскрипцию - это не украшение, а ключ к тому, чтобы автоматизация бизнеса n8n не превратилась в живописную схему, которую приходится выключать при первой проверке. Закон ожидает, что человек понимает, что его записывают, что дальше запись попадет в систему, где будет транскрибация аудио и видео, и что из этой транскрипции могут извлекаться обезличенные аналитические данные. Если вы собираете аудио через сайт или виджет, это значит, что форма согласия должна жить отдельно от общих «я согласен со всем», а в n8n должен существовать узел, который реально логгирует факт получения этого согласия с датой, временем и контекстом.
Чтобы не запутаться, я для себя держу в голове простой набор контрольных точек, которые потом перекладываются в узлы n8n и настройки CRM.
- Формулировка согласия явно упоминает запись и транскрибацию, а не просто «обработку данных».
- Согласие хранится как отдельный объект (например, в CRM или DPO-системе), а не как галочка без истории.
- n8n пишет в лог, когда и в каком контексте это согласие было получено или отозвано.
- При отзыве согласия срабатывает автоматический workflow на удаление/анонимизацию записей.
- Тексты согласий адаптированы под Российскую Федерацию и ссылку на 152-ФЗ, а не на абстрактные «международные стандарты».
Если хоть один пункт из этого списка выпал, автоматизация через n8n превращается в хрупкий домик: все красиво, пока никто не дергает за юридическую ниточку. А дергать её будут, особенно если вы работаете с массовыми пользовательскими данными. Я не говорю, что нужно сразу внедрять огромную систему комплаенса, но хотя бы минимальный реестр обработок и прозрачный лог действий сильно снижают риск того, что транскрибация аудио онлайн бесплатно внезапно окажется очень дорогой по штрафам. И да, когда вы дойдете до реальной схемы, мы вернемся к этим точкам, чтобы превратить их в конкретные узлы внутри n8n.
Зачем заморачиваться с white-data и обезличиванием
Если честно, идея white-data поначалу звучит как что-то из методичек, пока не пытаешься ответить на простой вопрос: «А можем ли мы отдать эти данные на анализ внешней команде, не раскрыв персональные данные клиентов?» В транскрибации это всплывает моментально: вы хотите анализировать темы обращений, эмоции, упоминания брендов, а в текстах полно имён, адресов, паспортов и других радостей. Это означает, что без обезличивания вы либо запираете данные внутри узкого контура и лишаете себя нормальной аналитики, либо бегаете по согласиям при каждом совместном проекте. Правильно настроенная автоматизация через n8n позволяет встроить обезличивание прямо в конвейер: сразу после транскрибации запускается модуль, который ищет и маскирует персональные данные по правилам и моделям.
Я обычно объясняю командам, что white-data - это не про «нарисовать звёздочки на экране», а про воспроизводимую методику, которую можно показать регулятору и не покраснеть.
Обезличивание считается рабочим не тогда, когда «так договорились с аналитиком», а когда вы можете открыть документ с описанием метода, показать логи работы и убедительно объяснить, почему восстановить личность по данным почти нереально.
Внутри n8n это выглядит довольно приземленно: один узел принимает текст транскрипции, другой прогоняет регулярки по телефонам и паспортам, третий, возможно, стучится к локальной NER-модели для распознавания имён и адресов, четвертый сохраняет две версии текста - исходную и обезличенную - в разные хранилища с разными правами доступа. И да, это не «быстро скрутили прототип вечером после работы», но именно такой подход позволяет честно говорить, что у вас есть автоматизация n8n, работающая в white-data-зоне. Чуть дальше я покажу, как встроить этот блок в общую архитектуру, чтобы он не жил отдельной странной надстройкой над остальным конвейером.
Как выстроить архитектуру автоматизации через n8n и Whisper API по‑взрослому
Когда я сажусь рисовать архитектуру автоматизации процессов n8n для транскрибации, я мысленно делю путь записи на несколько станций: сбор и согласие, первичное хранение в РФ, транскрибация, пост-обработка, обезличивание, аналитика и удаление по срокам. Если какая-то из станций выпадает, вся система начинает шататься: можно иметь идеальную модель Whisper, но при этом хранить аудио без шифрования и прозрачных сроков, или наоборот - блестящую DPO-документацию, но транскрибацию аудио и видео на зарубежных серверах. Задача n8n здесь - не просто «соединить точки», а стать тем самым оркестратором, который держит весь жизненный цикл данных под контролем, включая не самые гламурные вещи вроде журналирования и отработки отказов. Это критично, потому что дальше на эту архитектуру будут опираться и ai агенты, и автоматизация с n8n для аналитики и оповещений.
Чтобы было проще держать картинку в голове, я люблю показывать плоскую, но понятную схему, где каждая стрелка - это не только техническая интеграция, но и юридическая история про «кто, где и зачем тронул данные». В одном из материалов я как раз сводила все эти линии в наглядную диаграмму.

Если пройтись по станциям подробнее, получается такая логика. Сначала запись попадает в точку сбора: сайт, виджет, мессенджер, IP-телефония колл-центра. Там же фиксируется согласие и минимальные метаданные, всё это падает в хранилище в РФ с шифрованием. Уже оттуда n8n подхватывает файл, приводит его к нужному формату, режет на куски, если нужно, и передает в модуль транскрибации - это может быть локально развернутая модель Whisper или коммерческий API, который гарантированно крутится в российской инфраструктуре. После получения текста включается этап пост-обработки: коррекция, форматирование, разметка, а затем - блок классификации ПДн и обезличивания. В конце данные либо попадают в CRM/аналитику, либо удаляются или маскируются по заданным правилам.
Здесь полезно подчеркнуть одну, казалось бы, очевидную деталь, про которую часто забывают.
Если вы строите архитектуру транскрибации в России, то вопрос «где физически крутится каждая часть пайплайна» не менее важен, чем «насколько быстро работает модель».Я не раз видела проекты, где всё упиралось не в скорость транскрибации, а в то, что кусок системы внезапно жил в зарубежном облаке, о чём вспомнили только после первых юридических вопросов. Поэтому, когда вы планируете систему автоматизации n8n, имеет смысл сразу думать категориями «контур РФ» и «контур внешних сервисов», оставляя второй только под обезличенные данные или под те сценарии, где у вас есть очень чёткое юридическое обоснование передачи.
Как выбрать между локальной моделью и внешним Whisper API
Самый частый спор, который я слышу на проекте: «нам проще дергать готовый API, зачем городить свой сервер с GPU и локальной сборкой Whisper». Ответ, как водится, зависит от того, что именно к вам приходит в аудио. Если там есть персональные данные граждан РФ, а тем более потенциальная биометрия голоса, то использование зарубежного API для первичной транскрибации выглядит, мягко говоря, рискованно. Я обычно рассматриваю два рабочих варианта: локальное развёртывание модели Whisper в инфраструктуре в РФ или договоренности с провайдером, который подтверждает размещение своих мощностей в России и даёт вам нормальные документы. В первом случае вы берёте на себя заботу о сервере и поддержке, во втором - о юридическом контроле и проверке поставщика.
Чтобы не превращать это в религиозный спор, полезно спокойно разложить факторы, которые важны именно для вашего кейса, и честно сопоставить их с возможностями команды.
Локальная модель обычно выигрывает по контролю и соответствию 152-ФЗ, а готовый API - по скорости старта и ресурсам команды. Вопрос только в том, готовы ли вы платить за удобство потенциальными рисками передачи ПДн.
Когда я делаю архитектуру для консервативных отраслей - финансы, медицина, гос-сегмент - мы почти всегда уходим в локальную модель, развёрнутую в отечественном облаке с аттестациями. Там n8n общается с моделью через внутренний API, и ни один байт аудио не уезжает за периметр. В более лёгких кейсах, где транскрибация аудио онлайн бесплатно нужна для обезличенных внутренних подкастов или обучающих созвонов, можно рассмотреть и гибридные варианты, но всё равно с проверкой провайдера на адекватность. И да, иногда команда после честного расчёта понимает, что им проще начать с малого: ограничить набор сценариев, снизить объём и постепенно двигаться к более защищённой конфигурации по мере роста.
Как организовать хранение, логи и удаление так, чтобы не стыдно было аудитору
Чаще всего самые непривлекательные части архитектуры оказываются самыми решающими в момент проверки: где лежат файлы, кто видит логи, как устроено шифрование и что происходит, когда пользователь попросил удалить данные. В автоматизации через n8n это можно сделать довольно элегантно: настроить триггеры по расписанию, которые по реестру обработок проходят по хранилищу и выполняют нужные операции. Но сначала нужно честно ответить себе на вопросы: сколько времени вам действительно нужно хранить аудио, зачем вы оставляете исходный файл после транскрибации, кто имеет доступ к тексту и как вы будете доказывать, что все эти правила соблюдаются. Это критично, потому что именно здесь чаще всего происходят провалы - файлы «на всякий случай» годами лежат на общем файловом ресурсе, а ноды n8n пишут в логи больше, чем нужно, и никто не контролирует, кто их читает.
Когда я проектирую такую часть системы, мне нравится держать под рукой общую архитектурную схему, где видно, как связаны хранилище, транскриптор, n8n и DPO-инструменты.

Я заметила, что хорошая практика - сразу разделять хранилище на несколько уровней: краткоживущее для сырых аудио, основное для транскриптов и отдельное обезличенное для аналитики. В n8n это выражается в явных ветках workflow: после успешной транскрибации узел удаляет исходный файл или перемещает его в «карантин» с жёстким сроком хранения, а обезличенный текст маркируется тегами и уходит в системы отчётности. Параллельно в журнал действий летит запись о том, кто и на каком основании получил доступ к исходным данным. Казалось бы, лишняя бюрократия, но через год, когда вы откроете этот лог в ответ на запрос, вы очень поблагодарите себя прошлую за такое занудство. Чуть позже мы переведём это в более прикладной язык узлов и связей в конкретном workflow.
Как собрать n8n workflows автоматизации для транскрибации шаг за шагом
Когда доходит до реальной сборки, всё становится гораздо приземленнее: вы сидите перед пустым canvas в n8n и думаете, с какого триггера начать. Я обычно иду от источников аудио: это может быть папка в S3-совместимом хранилище в РФ, webhook от IP-телефонии, новая запись в CRM или файл, брошенный в канал в корпоративном мессенджере. От выбранного триггера зависит структура остального workflow, но общая логика похожа: принять файл, проверить метаданные и согласие, привести к нужному формату, отправить на транскрибацию, обработать текст, сохранить нужные версии и запустить обезличивание. Автоматизация n8n здесь хороша тем, что позволяет без глубокого программирования собрать эту цепочку, а потом постепенно донаращивать сложности по мере взросления процесса.
Чтобы не говорить слишком абстрактно, я опираюсь на типовую схему, где видно все ключевые этапы от приёма до аналитики. Она помогает объяснить и айтишникам, и бизнесу, что происходит под капотом, когда звонок превращается в аккуратный текст в CRM.
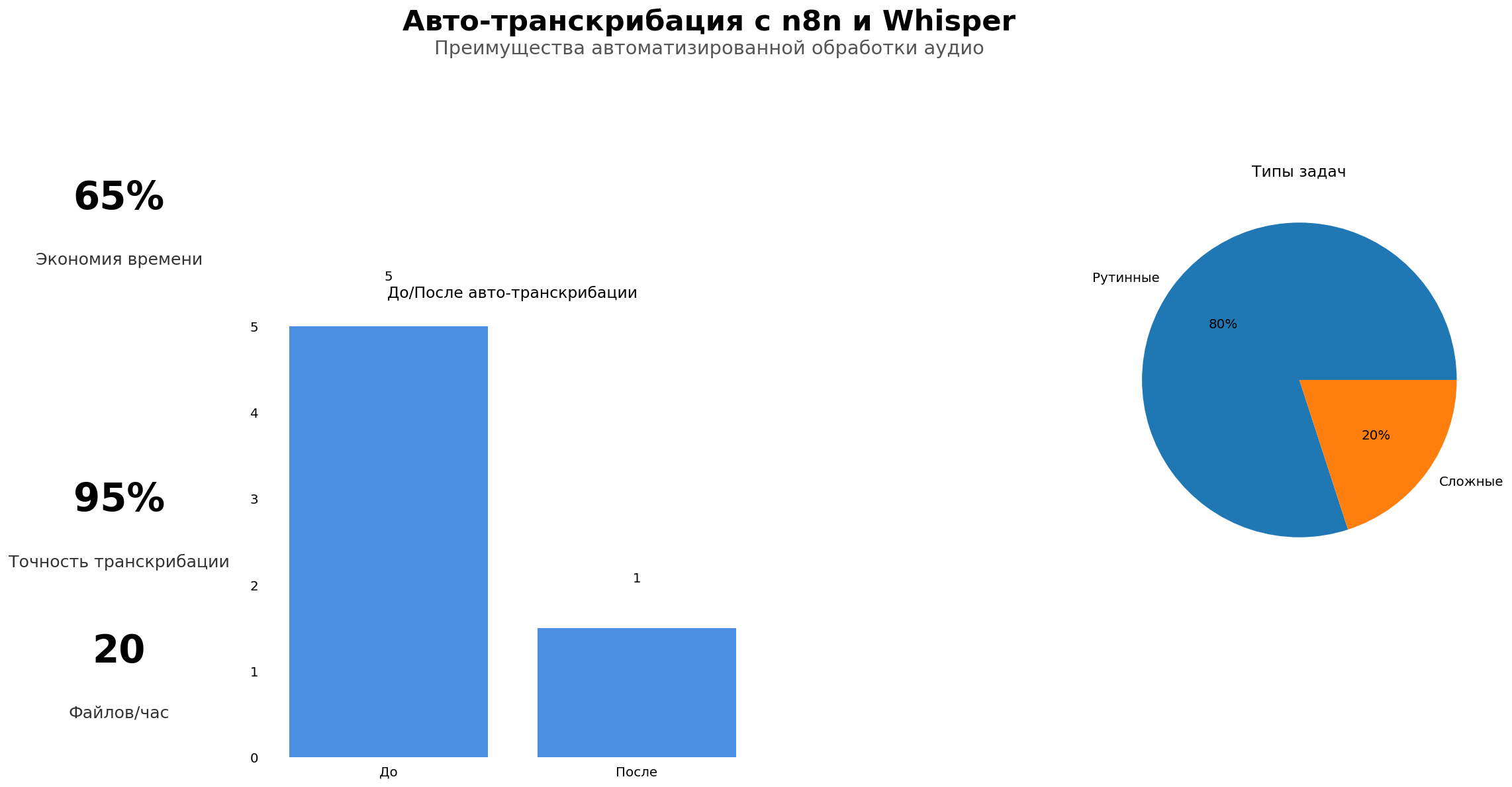
Первая ветка обычно занимается подготовкой: нормализует формат аудио (частота, тип файла), режет длинные записи на удобные куски, добавляет технические теги и проверяет, есть ли в системе валидное согласие пользователя. Вторая ветка отвечает за транскрибацию: берёт каждый кусок и отправляет его либо в локальный endpoint Whisper, либо в проверенный API в РФ, а затем собирает обратно в единый текст, аккуратно уложенный по тайм-кодам, если это нужно. Третья ветка - пост-обработка: домапливает спикеров, исправляет часто встречающиеся ошибки распознавания, приводит всё к формату, удобному для дальнейшей аналитики или загрузки в CRM. И только четвёртая ветка занимается обезличиванием и подготовкой данных к тому, чтобы покинуть внутренний контур, если это вообще планируется.
Здесь полезно помнить, что n8n не ограничивается встроенными нодами: вы всегда можете добавить свои маленькие скрипты для специфических проверок, маскировок или форматирования. Сила системы автоматизации n8n в том, что она позволяет собрать один сквозной конвейер от аудио до white-data, а не держать три разрозненных скрипта, о которых помнит только один человек в отделе. Многое здесь завязано на дисциплину: если вы сразу договоритесь в команде, какие узлы отвечают за что и как вы именуете переменные, сопровождать такой workflow будет значительно проще, чем кажется на этапе первого прототипа.
Какие шаги я почти всегда включаю в рабочий workflow
На практике у меня сформировался набор шагов, которые перекочёвывают из проекта в проект с вариациями. Они охватывают все ключевые точки от приёма файла до отдачи результата и помогают не забыть про важные мелочи. Чтобы не перегружать теорией, я просто перечислю те блоки, которые чаще всего оказываются в продовой схеме для транскрибации аудио онлайн.
Триггер на новый файл или событие, нормализация аудио, проверка согласия, вызов модели транскрибации, сбор и проверка текста, обезличивание, сохранение разных версий и журналирование каждого шага - вот та «скелетная» схема, с которой уже можно жить.
Каждый из этих шагов легко масштабируется: проверка согласия может быть как обращением в одну таблицу, так и сложным запросом к системе комплаенса; обезличивание - от пары регулярных выражений до полноценной NER-модели на отдельном сервере. Автоматизация через n8n хороша тем, что позволяет вам начать с простого, а потом наращивать сложность точечно, не переписывая всё с нуля. Я редко встречала проекты, где первый прототип не пришлось бы перепиливать спустя пару месяцев, но если изначальный каркас был продуман, эти изменения ощущаются как плановое развитие, а не как боль и страдания по ночам.
Важная деталь: имеет смысл сразу заложить уведомления и мониторинг. n8n умеет слать алерты в тот же Telegram или почту при ошибках, и гораздо приятнее узнать о проблеме от бота через 5 минут, чем от разъярённого менеджера через неделю. Здесь придётся чуть потерпеть и аккуратно настроить уровни важности, чтобы вам не спамили по каждой мелочи, но это окупается при первом же нестабильном апдейте модели или провайдера.
Как визуализация помогает договориться с бизнесом и безопасностью
Я заметила, что как только разговор про транскрибацию уходит в детали, у разных команд в голове рождаются совершенно разные картинки. Разработчики видят узлы и API, бизнес - «чудо-кнопку, которая сама всё расшифрует», безопасность - возможные утечки и штрафы. В такие моменты сильно выручает визуальное представление процесса, где на одной схеме показаны и шаги автоматизации n8n, и точки, которые критичны для комплаенса. Это может быть даже не UML, а простая дорожка из блоков: здесь принимаем файл, тут проверяем согласие, тут работаем с Whisper, вот здесь обрезаем доступ к сырым данным. Главное, чтобы каждый участник разговора видел, где его зона ответственности, и мог задать конкретные вопросы.
В одном из разборов я как раз собирала такой визуальный блупринт решения для конвейера транскрибации, и его потом несколько раз переиспользовали как основу для реализации в разных командах.
Такая картинка помогает не только на старте, но и потом, когда к проекту подключаются новые люди: достаточно один раз пройтись по схеме, чтобы не рассказывать с нуля, почему нельзя «просто кинуть все записи в удобный западный сервис». Чем прозрачнее выглядит ваш процесс на картинке, тем легче его защищать перед аудиторами и тем проще отлавливать узкие места, когда объёмы вырастают в разы. И да, я искренне рекомендую сохранять эти схемы рядом с описанием workflow в вашем внутреннем вики или на сайте проекта, чтобы через полгода вы сами себе могли быстро напомнить, что и зачем вы сделали именно так.
Каких результатов ждать от автоматизации процессов n8n в транскрибации
Когда разговор заходит о результатах, обычно все ждут магические проценты: на сколько сократится время обработки звонка и когда окупится сервер с GPU. Я отвечу честно: универсальной цифры нет, но есть типичные коридоры. В небольших компаниях, где часы транскрибации считались буквально руками, переход на автоматизацию через n8n чаще всего снимает 70-80% ручного труда уже в первые месяцы. В колл-центрах посерьёзнее эффект выражается не только во времени, но и в качестве: когда у вас наконец-то есть полные тексты звонков, а не выборочная выборка, и когда аналитика строится по всей массе, а не по «случайным 10 записям за прошлую неделю». При этом, если вы изначально заложили работу в white-data-зоне, вы можете делиться обезличенными текстами с внешними аналитиками, не устраивая каждый раз юридический цирк.
В одном из кейсов для малого бизнеса мы считали, во сколько обходится ручная транскрибация аудио в текст онлайн бесплатно с помощью штатных сотрудников. Оказалось, что при объёмах больше 100 часов в месяц, даже относительно скромный сервер с Whisper и n8n окупается за 3-6 месяцев только за счёт высвобождения времени. Я подчёркиваю: это не точный ROI для всех отраслей, а ориентир, который помогает прикинуть порядок величин.
Автоматизация n8n в зонах с повторяющимися задачами почти всегда окупается быстрее, чем мы думаем, просто потому что человек плохо чувствует стоимость своего времени на мелких действиях.
Если добавить к этому снижение рисков ошибок (человек банально устает и пропускает детали в расшифровке), получается довольно мощный операционный эффект. Я иногда шучу, что автоматизация бизнеса n8n начинается с того момента, когда вы находите в процессе человека, который регулярно делает одно и то же больше часа в день и искренне считает это нормой. В транскрибации это особенно заметно: сегодня вы экономите пять минут на одном звонке, завтра - пару рабочих дней на проекте, а через год у вас уже целый чат «бывших расшифровщиков», которые занимаются куда более интересными задачами.
Если смотреть шире, транскрибированные и обезличенные данные становятся сырьём для новых продуктов: поиск по разговорам, умные подсказки операторам, обучение ИИ-агентов на реальных диалогах с клиентами. Здесь тоже н8n отлично заходит как клей, соединяющий транскрибацию, CRM, аналитику и, например, внутренние чат-боты. Это не происходит мгновенно, но когда конвейер транскрибации уже стабилен, следующая ступень развития приходит довольно естественно.
Что получает малый бизнес и одиночные практики
Я часто работаю с небольшими командами и экспертами, у которых нет отдельного ИТ-отдела, зато есть много записей консультаций и вебинаров. У них запрос чуть другой: не построить гигантскую систему, а сделать так, чтобы транскрибация аудио в текст онлайн бесплатно не съедала творческое время. В одном таком проекте мы развернули n8n на VPS в РФ, подключили локальную сборку Whisper на недорогом GPU и настроили простой конвейер: запись бросается в папку, n8n подхватывает её, транскрибирует, маскирует номера телефонов и складывает текст в удобную базу, откуда уже берутся фрагменты для статей и постов. Через пару недель у автора появилось ощущение, что «контент делается сам», хотя под капотом пахали вполне приземлённые узлы и скрипты.
Чтобы зафиксировать, как меняется жизнь в таких кейсах, я обычно формулирую это так.
Когда транскрибация уходит в автоматический конвейер, консультации и созвоны перестают быть «разыгранным и забытым спектаклем» и превращаются в системный источник материалов и идей.При этом малому бизнесу и сольным практикам особенно важно не забывать про 152-ФЗ: даже если вы записываете «всего пару клиентов в неделю», закон не делает скидку на масштаб. Поэтому я всегда рекомендую хотя бы минимально оформить согласия и настроить хранение так, чтобы аудио не лежали годами в незащищенных папках. Автоматизация через n8n в этом смысле даже упрощает жизнь: вы один раз настраиваете, что и куда перекладывается, и перестаете полагаться на память и аккуратность в ночную смену.
Как меняется работа колл-центров и продуктовых команд
У средних компаний и колл-центров фокус слегка другой: им критично сократить время обработки обращения и получить более-менее полную картину диалогов. В одном из проектов колл-центр уже записывал звонки, но почти не использовал их, кроме как по жалобам. После внедрения автоматизации процессов n8n с транскрибацией в контуре российского облака с аттестациями выяснилось, что операторы тратят меньше времени на последующее оформление, потому что часть структуры разговора уже подтягивается автоматически. Плюс, руководители получили доступ к дэшбордам по темам и тональности обращений, а отдел качества - к выборке «сложных» разговоров, автоматически помеченных по ключевым словам.
Я заметила, что продуктовые команды особенно ценят возможность быстро искать по базе разговоров по конкретным запросам пользователей: это меняет подход к исследованиям. Вместо того чтобы вспоминать, «кто это говорил полгода назад», можно за пару минут найти десяток реальных цитат. Транскрибация аудио онлайн превращает звонки и созвоны в живую базу знаний, если поверх неё построен разумный поиск и фильтры. Всё это, конечно, работает только тогда, когда изначальная архитектура транскрибации и хранения была продумана: иначе поиск превращается в рискованный поход по сырым данным, где вперемешку лежат обезличенные и вполне идентифицируемые записи.
Что чаще всего ломается в проектах транскрибации и почему
После нескольких внедрений у меня сложился небольшой музей типичных ошибок, которые повторяются с пугающей регулярностью. На первом месте - любовь к зарубежным API без оглядки на локализацию: звучит заманчиво, когда сервис обещает «лучшую точность транскрибации аудио онлайн бесплатно или почти бесплатно», но потом оказывается, что база граждан РФ фактически ушла за границу. На втором месте - игнорирование отдельного согласия на запись и транскрибацию, особенно в мелких проектах, где кажется, что «мы же просто сохраняем голосовые клиентов». На третьем - хаотичное хранение: аудио и транскрипты живут годами без понятных сроков, попадая в бесконечные бэкапы и архивы. Всё это делает автоматизацию n8n скорее ускорителем проблем, чем их решением, если не задать рамки заранее.
Чтобы наглядно показать, где обычно происходит расхождение между «как делаем» и «как надо было бы», я однажды свела эти ошибки в сравнительную инфографику. Она хорошо работает на воркшопах, когда нужно мягко, но честно показать команде, что их любимый способ «сначала запускаем, потом думаем» здесь очень опасен.

Отдельная история - недоверие к собственному обезличиванию. Иногда команды честно накручивают регулярки и модели, но при первой же проверке оказывается, что достаточно пары связок «город + редкая должность», чтобы идентифицировать человека. Здесь помогает взгляд со стороны и небольшое внутреннее тестирование: попросите несколько сотрудников попробовать «догадаться», кто скрыт за обезличенным текстом, основываясь на косвенных признаках. Если угадываемость выше чистой случайности, методику стоит пересмотреть. Я понимаю, что звучит это чуть параноидально, но именно на таких нюансах потом строятся претензии при проверках.
Ещё один частый просчёт - забытый голос как биометрический признак. Пока вы используете аудио только как сырьё для текста и не строите на голосе систему аутентификации, ситуация понятнее. Но стоит кому-то в компании сказать «а давайте авторизовываться по голосу в боте», как вы внезапно оказываетесь в мире особых требований к биометрии. Здесь моя практика простая: как только заходит речь о голосе как о факторе идентификации, я предлагаю сразу привлекать юристов, специалистов по ИБ и смотреть, а тянет ли бизнес-кейс на все эти танцы. В большинстве случаев оказывается, что нет, и идея тихо уходит с повестки.
Какие заблуждения про n8n и транскрибацию встречаются чаще всего
Иногда на консультациях слышу фразы, от которых внутренний аудитор во мне грустно берётся за чай. Самое популярное - «если использовать Whisper через API, это автоматически законно, там же всё безопасно по умолчанию». Нет, так не работает: для России критично, где стоят сервера, по какому праву живёт поставщик, как построены договоры и что именно написано в политиках. Второе заблуждение - «обезличил текст, вопрос решён». Нет, важно не только то, что вы заменили имя на «Клиент», а то, насколько методика препятствует обратной идентификации при доступе к дополнительным данным. Третье - «n8n это игрушка для простых задач, всё серьёзное должно быть на коде». На практике автоматизация процессов n8n очень хорошо тянет и сложные конвейеры, если вы относитесь к ней как к взрослой системе, а не к вечному черновику.
Чтобы мягко, но чётко развенчать эти мифы, я иногда формулирую это одной фразой.
Технология сама по себе редко нарушает закон, его нарушает архитектура и способ её использования.В контуре транскрибации это особенно ярко: та же модель Whisper может быть как частью аккуратной системы в российском облаке, так и неосознанным мостом для утечки ПДн в неизвестном направлении. И n8n в этой истории - не магический белый рыцарь, а всего лишь гибкий инструмент, который честно реализует всё, что вы в него заложили. Поэтому я всегда стараюсь сочетать разговоры о нодах и API с разговором о том, куда именно и при каких условиях мы эти ноды подключаем. Это помогает командам смотреть на автоматизацию не только через призму «как бы нам быстрее», но и «как бы нам потом спокойно спать».
Как чинить уже запущенный, но рискованный процесс
Иногда ко мне приходят не на этапе планирования, а когда всё уже работает: транскрибация аудио онлайн настроена, бизнес доволен, но где-то в углу начинает шевелиться мысль «а вдруг мы так жить не можем». В таких случаях я обычно иду по пути минимально болезненной миграции: сначала инвентаризируем источники аудио и точки выхода данных наружу, потом смотрим, какие куски пайплайна можно перетащить в российскую инфраструктуру без остановки сервиса, параллельно оформляя согласия и документацию. Да, это не всегда приятно, особенно когда придётся отказаться от части удобных, но небезопасных интеграций, но это всё же лучше, чем ждать, пока кто-то снаружи сделает этот выбор за вас.
Очень помогает честный разговор с командой: лучше прямо сказать «мы сделали быстро, теперь приведём это в соответствие», чем притворяться, что вопросов нет. На моей памяти несколько таких проектов прошли довольно мягко, именно потому что бизнес увидел в этом не только «юридический страх», но и шанс на улучшение качества и прозрачности процесса. Я иногда шучу (немного криво, но от души), что внутренний аудит - это не про поиск виноватых, а про золотую возможность пересобрать то, что давно хотелось пересобрать. И в истории с транскрибацией через n8n это, как ни странно, часто оказывается правдой.
Как стартовать безопасно: мой базовый чек‑лист действий
Когда теории и страшилок уже достаточно, возникает вполне приземлённый вопрос: с чего начать, чтобы автоматизация n8n для транскрибации не превратилась в вечный долгострой. Я обычно предлагаю двигаться по лестнице из нескольких шагов: сначала разобраться, какие данные у вас вообще есть, потом определиться с архитектурой и провайдерами, затем собрать минимальный рабочий конвейер и только после этого наращивать красоту в виде аналитики и интеграций с ИИ-агентами. Этот подход особенно хорошо работает, если в компании нет отдельной команды по защите данных и вам нужно балансировать между скоростью внедрения и здравым смыслом по 152-ФЗ. Здесь нет волшебства - просто аккуратное движение без попыток одним прыжком перепрыгнуть с «ручной расшифровки» к «умному ассистенту, который сам всё понимает».
Чтобы зафиксировать логическую последовательность, я люблю показывать командам компактную схему, где каждый шаг отражён отдельно, но при этом видно, как они собираются в общую картину. В одном из материалов я как раз раскладывала по полочкам такую пошаговую инфографику, и её потом много раз просили прислать как напоминание.
На практике на старте я прошу команду честно ответить на шесть вопросов: есть ли в аудио персональные данные граждан РФ, зафиксированы ли цели обработки, понятны ли сроки хранения, где именно физически крутится инфраструктура, кем и как оформляются согласия и кто будет смотреть на логи и отчёты по инцидентам. Если на один из пунктов ответ «не знаем» или «как-нибудь потом», это хороший сигнал немного притормозить с подключением новых сервисов и сначала навести порядок в основе. Здесь нет задачи сделать идеальный проект сразу, но чем чище вы стартуете, тем меньше потом придётся переподнимать всё ради соответствия требованиям.
Если вы хотите посмотреть, как я подхожу к разбору подобных задач и другим кейсам автоматизации, можно заглянуть на мой сайт о практической автоматизации через n8n и ИИ - там я собираю разборы, схемы и рабочие подходы без магии и хайпа. Я не обещаю, что после одной статьи вы станете архитектором по транскрибации, но точно станет легче сформулировать требования к своему первому пилоту.
Какой порядок действий я обычно предлагаю командам
Когда нужно перевести всё сказанное в набор шагов, я стараюсь не перегружать команды десятками пунктов. Обычно мы фиксируем короткий порядок действий на ближайшие недели, и этого достаточно, чтобы сдвинуться с мёртвой точки, не ломая текущие процессы.
- Шаг: провести инвентаризацию источников аудио и понять, где в них персональные данные.
- Шаг: выбрать инфраструктуру в РФ для хранения и развёртывания n8n и модели транскрибации.
- Шаг: подготовить отдельные формы согласий и механизмы их логгирования.
- Шаг: собрать первый сквозной workflow в n8n с минимальным набором шагов.
- Шаг: внедрить базовое обезличивание и протестировать его на реальных данных.
- Шаг: настроить политику хранения и автоматического удаления, задокументировать её.
После такого минимального цикла уже есть с чем идти и к руководству, и к безопасности: вы показываете не презентацию мечты, а живой конвейер, который можно пощупать и улучшать. Я заметила, что команды гораздо охотнее дорабатывают то, что уже приносит пользу, чем строят что-то абстрактное «под требования». Поэтому я за то, чтобы первый вариант был пусть простым, но рабочим и легальным, а не идеальным только в слайдах. Дальше можно уже думать про сложные аналитические слои, ИИ-агентов и другие красивые штуки.
Что остается за кадром, но сильно влияет на успех
Когда я сажусь финально разложить проект транскрибации для себя, в блокнот почти всегда попадают не только узлы n8n и модели, но и люди: кто будет отвечать за процесс, кто за инциденты, кто за обновление моделей и документации. Без этого любая автоматизация через n8n рискует превратиться в «черный ящик», который однажды перестанет работать ночью перед дедлайном. В российских реалиях к этому добавляется ещё один слой - контакт с DPO или тем, кто отвечает за персональные данные. Если не договориться с ними на берегу, вы рискуете сделать технически красивый, но нежизнеспособный конвейер, который при первой проверке попросят серьёзно переработать.
Я заметила, что здорово работает практика коротких ревью: раз в квартал устраивать небольшой внутренний аудит конвейера транскрибации. Проходите по ключевым вопросам: не поменялись ли источники аудио, не выросли ли объёмы так, что текущая инфраструктура уже дышит на ладан, не появились ли новые требования по 152-ФЗ, всё ли в порядке с документами по white-data. Автоматизация - это не проект, который можно «сдать и забыть», а сервис, который живёт вместе с компанией, её продуктами и законами вокруг.
И ещё один момент, который часто недооценивают: внутренняя грамотность команды. Даже самый красивый конвейер можно поломать, если сотрудники не понимают, что можно, а что нельзя отправлять в транскрибацию, как работать с обезличенными текстами и к кому бежать, если что-то пошло не так. Здесь очень помогают короткие обучающие материалы и понятные инструкции без канцелярита. Я иногда собираю для клиентов мини-гайды в духе «что делать, если у вас есть запись звонка и вы хотите превратить её в текст легально» - и это снижает количество хаотичных инициатив в несколько раз.
Куда двигаться дальше, если хочется не только читать, но и делать
Если ты дочитала до этого места и всё ещё чувствуешь в себе силы и интерес, то, скорее всего, тебе уже не хватает просто теоретических рассуждений. Наверно, есть свои записи, звонки, вебинары, где транскрибация аудио в текст могла бы реально разгрузить день и освободить голову под более интересные задачи. Я бы предложила не откладывать первый маленький шаг: выбрать один понятный источник аудио, настроить для него простой, но аккуратный workflow в n8n и посмотреть, как изменится твой рабочий день, когда часть рутины уйдёт в автоматический конвейер.
Если хочется больше живых разборов и схем по автоматизации через n8n, Whisper и другим ИИ-инструментам, можно заглянуть в мой телеграм-канал про практическую автоматизацию MAREN - там я регулярно разбираю кейсы, делюсь рабочими находками и иногда показываю те самые ноды, которые экономят по пару часов в день. А за более структурированными материалами и описанием того, чем я занимаюсь как AI Governance & Automation Lead, можно зайти на сайт студии MAREN - там живут гайды, схемы и истории внедрений без магических обещаний, только с тем, что реально помогает вернуть себе время.
Что ещё важно знать про n8n и транскрибацию аудио
Нужно ли обязательно разворачивать Whisper локально в России, чтобы не нарушать 152-ФЗ
Если в аудио есть персональные данные граждан РФ, то первичная обработка действительно должна происходить в контуре РФ. Локальное развёртывание Whisper или работа с провайдером, который гарантирует российскую инфраструктуру, снижают риски и упрощают общение с регулятором. При использовании зарубежного API без исключений вы можете столкнуться с претензиями по локализации ПДн.
Можно ли использовать автоматическую транскрибацию только для внутренних совещаний без согласий
Даже если вы расшифровываете внутренние встречи, в записях могут быть персональные данные сотрудников. Формально это тоже обработка ПДн, и лучше иметь понятные внутренние регламенты и уведомление сотрудников о записи и последующей транскрибации. Это снижает риски конфликтов и вопросов от службы безопасности и HR.
Что делать, если часть исторических записей уже транскрибирована через зарубежный сервис
В такой ситуации имеет смысл провести инвентаризацию этих данных и оценить риски: какие записи, какие категории ПДн, кто имел доступ. Дальше можно принять решение об их удалении, дополнительном обезличивании или ограничении доступа, задокументировав этот шаг. Параллельно стоит перестроить текущий процесс в пользу локальных или российских решений.
Как понять, что наше обезличивание текста действительно соответствует ожиданиям регулятора
Полной «серебряной пули» нет, но есть разумный подход: описать методику, протестировать её на реальных данных и оценить вероятность обратной идентификации. Если по обезличенному тексту всё ещё легко восстановить конкретного человека, методику стоит усилить. Документирование процесса и наличие логов сильно помогают при общении с проверяющими.
Можно ли обойтись без n8n и собрать всё только на скриптах и cron
Технически можно, особенно если у вас сильная разработческая команда и небольшой объём задач. Но n8n упрощает визуализацию, сопровождение и масштабирование, особенно когда в процесс вовлечены не только разработчики. Он даёт наглядный конвейер, который проще обсуждать с бизнесом, безопасностью и аудитором, чем россыпь отдельных скриптов.
Что делать, если точность транскрибации оказывается ниже ожидаемой
В такой ситуации стоит пройтись по нескольким точкам: качество исходного аудио, настройки препроцессинга, выбор модели и язык. Иногда достаточно улучшить запись или включить нормализацию шума, чтобы точность выросла. В других случаях приходится калибровать модель под доменную лексику или рассмотреть более мощную конфигурацию.
Есть ли смысл подключать ИИ-агентов поверх транскрибированных данных сразу на старте
Я бы не спешила: сначала лучше убедиться, что базовый конвейер транскрибации и обезличивания стабилен и понятен. Когда у вас есть надёжный поток качественного текста, подключать ИИ-агентов для анализа, резюмирования или подсказок становится намного безопаснее и полезнее. Иначе вы строите сложный слой поверх шаткого фундамента.


